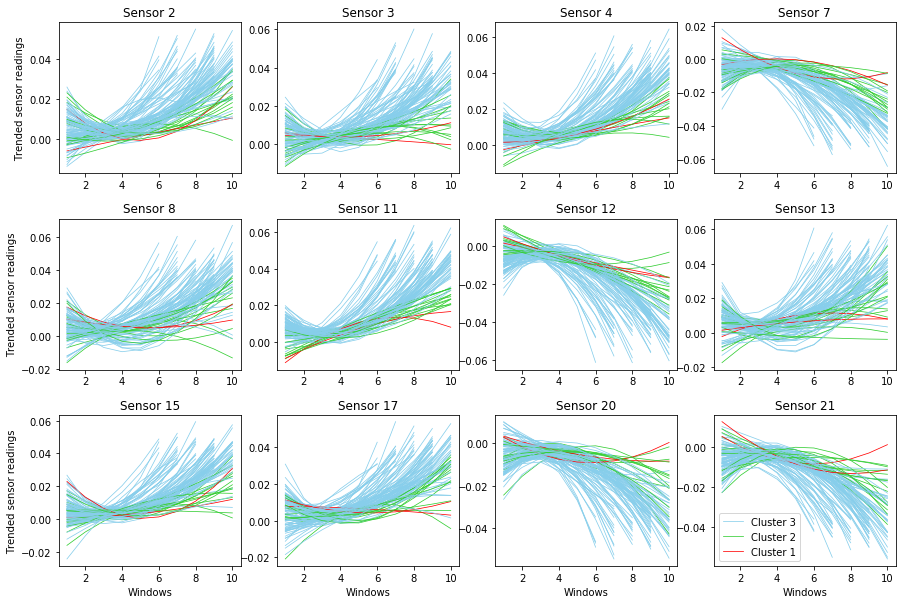
Splitting dataset for federated learning
In this post, we would explore how to split a dataset for the purpose of federated learning. Federated learning is applicable when there are multiple independent workers with isolated pools of private data. These pools of federated data can take the form of either a horizontal or vertical data set. A federated data set is said to be horizontal if the individually distributed data sets have homogeneous feature space as shown in the figure below.
This means that uniquely identifiable data points across each pool share the same features. A precursor to simulating and testing a horizontal federated learning model is therefore access to multiple sets of data with the same feature space across unique samples.
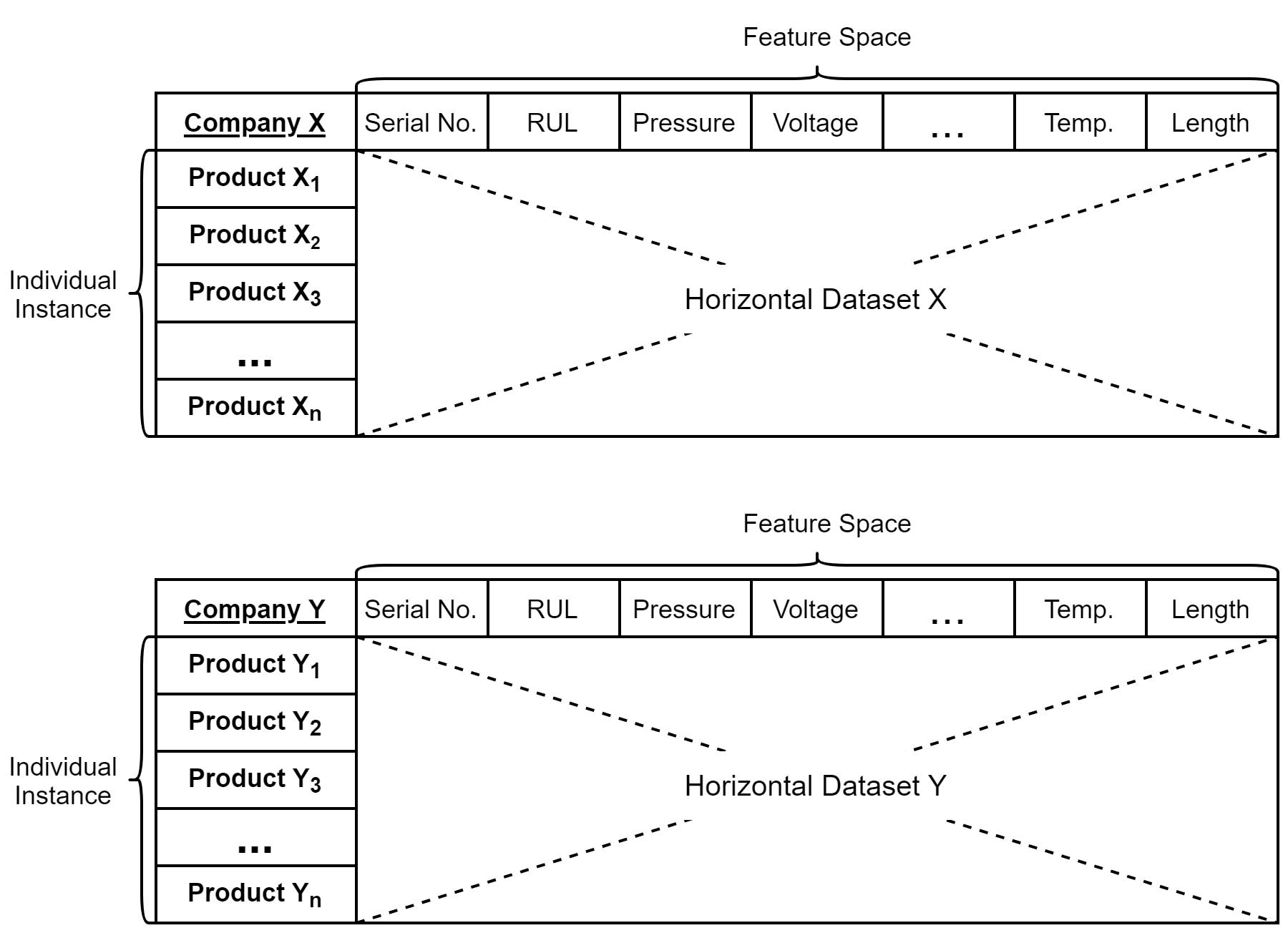
Introduction to turbofan engine dataset
This post relies primarily on the turbofan engine degradation simulation data set produced by Saxena et al., originally used as data in the 2008 Prognostics and Health Management (PHM) data competition. This data was generated using the Commercial Modular Aero-Propulsion System Simulation (C-MAPSS) tool, which is an engine simulation software used to simulate large commercial turbofan engine with 90,000 lb of thrust.
Four data sets are provided from this simulation, each representing a number of engines simulated under different combination of operating conditions and fault modes. For example, data set FD001 contains 100 engines simulated at sea level with only one possible failure event (HPC degradation) while data set FD004 contains 248 engines simulated under six different operating conditions with 2 unique failure event (HPC degradation and Fan degradation).
Engines in all data sets are simulated starting from an initial operating condition at cycle 1 with a maximum RUL, with the unit of time defined in operating cycles of the engine. The initial condition differs between engines with varying extent of wear and manufacturing variability. Three additional fields are provided in each data set, representing the different initial operating settings of each engine. Hence, each engine will encounter a failure event at different cycle in time.
Each data set is made up of a training and test subsets. Engines in the training set are simulated until the point of failure while engines in the test set may be censored before a failure event is encountered.
Dynamic Time Warping
The technique chosen to perform this split is time series hierarchical clustering using Dynamic Time Warping (DTW) as the distance metric [1]. DTW performs a pairwise comparison of data points in two time series to derive the extent of similarity (or difference) between each sequence. It can be applied to time series of varying length but aligned in terms of time, as is the case in FD001. The result of the clustering is shown in the figure below where each of the 100 engines are allocated to a cluster.
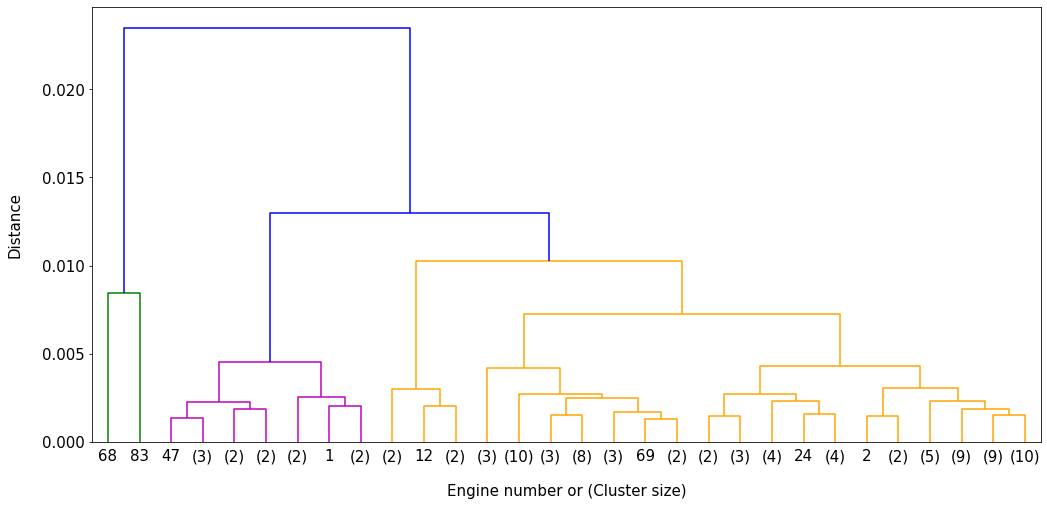
Three general clusters can be seen from this exercise which forms the basis of the split of FD001 into three imbalanced federated train data sets of size 85, 13 and 2 respectively. The fiure below shows the difference in trend between the 3 clusters.