

Insurance and social media: Keyboard warriors
Originally published by The Actuary, February 2021. © The Institute and Faculty of Actuaries.
Click here to read the original article.
John Ng and Melanie Zhang discuss how they analysed Twitter sentiment relating to COVID-19 and insurance – and how insurers could use such analysis
Twitter offers the public the opportunity to give their real-time thoughts on world events by posting short texts known as ‘tweets’. The COVID-19 pandemic was the defining event of 2020, which makes it a great subject for sentiment analysis – the use of natural language processing to automatically determine the emotion a writer is expressing in a piece of text – or tweets. We wanted to see if we could use Twitter data relating to COVID-19 in the UK to uncover insights pertinent to public interest and the insurance industry.
From unstructured data to sentiment prediction
Twitter is a goldmine of big data, involving more than 1bn user accounts that generate around 500m daily tweets – roughly 200bn tweets per year. This data comes with challenges, such as use of unconventional language, potential biases, and lengthy processing time. There are also a number of steps involved in preparing the data, building models and making sentiment predictions.
Step 1: Preparing the data
Twitter data is openly accessible to developers via Twitter’s application programming interface (API). We used the Twitter identification numbers (IDs) from 1 January to 22 November 2020, which were published in the study ‘COVID-19 Twitter chatter dataset for scientific use’ by Georgia State University’s Panacea Lab.
DocNow’s Hydrator was used to extract (‘hydrate’) the original tweets and metadata via these IDs. Twitter restricts the hydration rate, so we took a 25% sample of the full dataset and adopted a distributed approach to data mining. This resulted in 25m English tweets, for which hydration would take around 10 days using a single Twitter account.
User location data is noisy. We used techniques such as direct mapping, semi-structured mapping and Google’s Geocoding API to obtain 1.7m UK tweets.
Step 2: Training machine learning models
For supervised learning, a sentiment label needs to be assigned to each tweet. Manual labelling is labour-intensive, so we applied an automated binary classification approach based on tweets containing positive or negative emoticons – labelled ‘positive’ (eg positive emojis) or ‘negative’ (eg negative emojis) accordingly. Only a small subset of tweets contained strong sentiment emoticons. We used 7,000 emoticon-labelled tweets for training and manually labelled 3,000 tweets for testing, taken from 1 January to 26 April 2020.
We augmented our training set with the ‘sentiment140’ dataset, a non-COVID-19 labelled Twitter dataset; this brought our enriched training set to 200,000 labelled tweets, with equal numbers of positive and negative labels. This contributed to a larger vocabulary and could improve predictive performance.
Next, we carried out the pre-processing and encoding steps depicted in Figure 1. Encoding is the feature extraction step that converts a set of words (‘tokens’) into numerical vectors (‘features’).
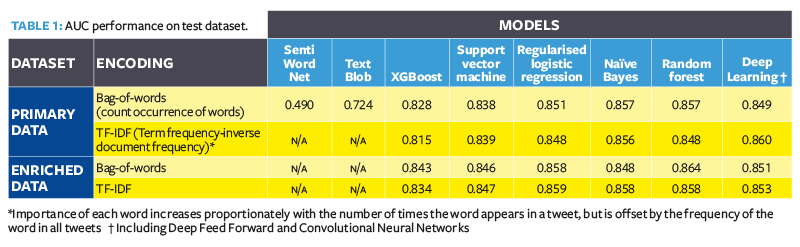
For each dataset, we explored a variety of machine learning algorithms and encodings to predict binary classification of positive (+1) or negative (-1) sentiment. The model performance metric is ‘area under the ROC curve’ (AUC), an aggregate measure of performance across all classification thresholds. We compared these against simple baseline models – SentiWordNet and TextBlob (open-source tools ready for ‘out-of-the-box’ use).
Based on results in Table 1, run-time and simplicity, our final selected model is regularised logistic regression with TF-IDF encoding trained on the enriched dataset. This achieved a 0.859 AUC. Fine-tuning machine learning models on a COVID-19-specific Twitter dataset can significantly outperform open-source tools.
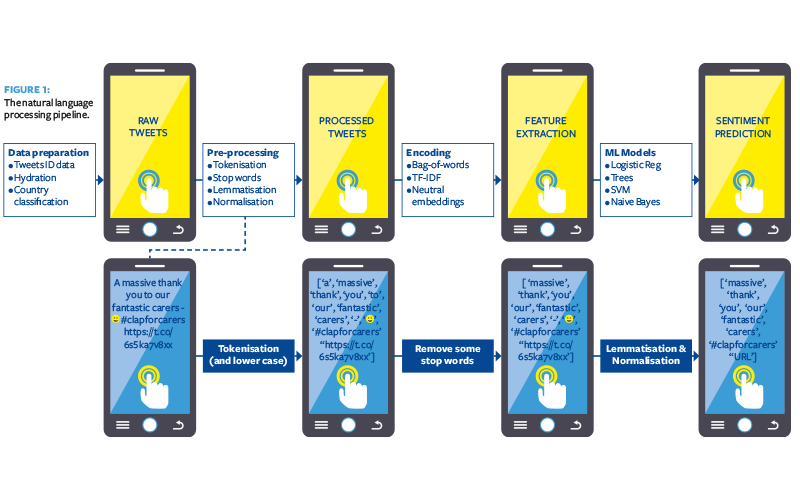
Step 3: Sentiment analysis
Our selected model was then used to assign individual sentiment scores to all 1.7m UK tweets. The resulting scores enable further analysis of overall trends over time, sentiment relating to specific topics, and underlying drivers.
Top concerns relating to coronavirus
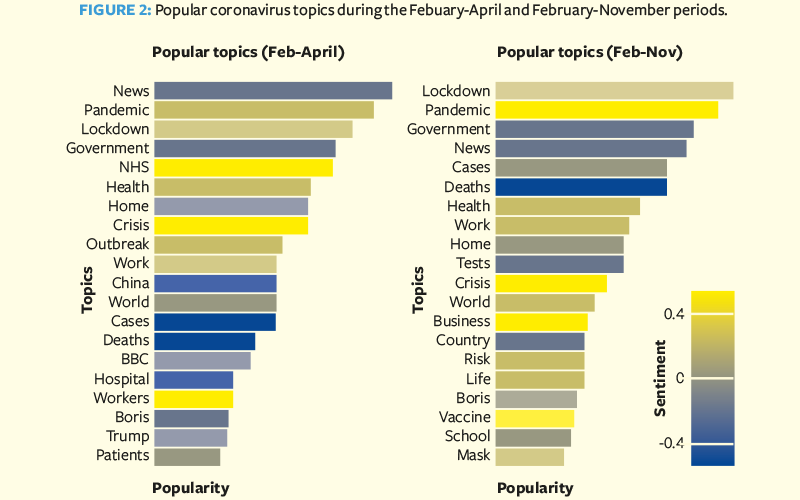
Figure 2 compares 20 of the most popular topics during the first wave versus during the whole duration of pandemic. Top-of-mind topics include ‘lockdown’, ‘government’, ‘deaths’, ‘cases’ and ‘health’.
The UK’s NHS was a frequent topic during the first wave, but not during subsequent months. It was associated with the positive sentiment resulting from the ‘clap for carers’ initiative, but there were dips in sentiment relating to fears over shortages of hospital beds and personal protective equipment. Discussion of ‘vaccines’, ‘school’ and ‘masks’ were relatively uncommon during the first wave but subsequently became mainstream.
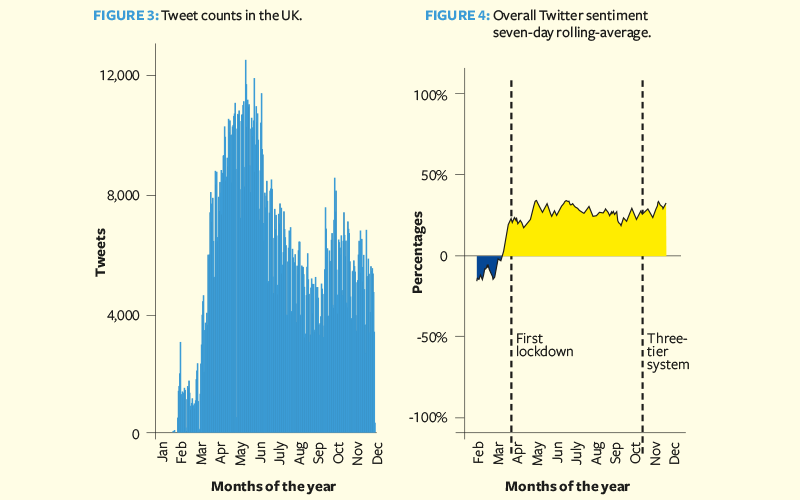
Sentiment analysis and overall trend
Tweets in February focused on COVID-19 development in other countries and carried a more negative sentiment. Since the inflection point in mid-March, overall sentiment has remained positive for the rest of the year. Sentiment towards the first lockdown was generally positive.
The granularity of text data enables us to perform deeper topical analysis by analysing the sentiment and context around certain words. We will look at two examples here: the words ‘government’ and ‘insurance’.
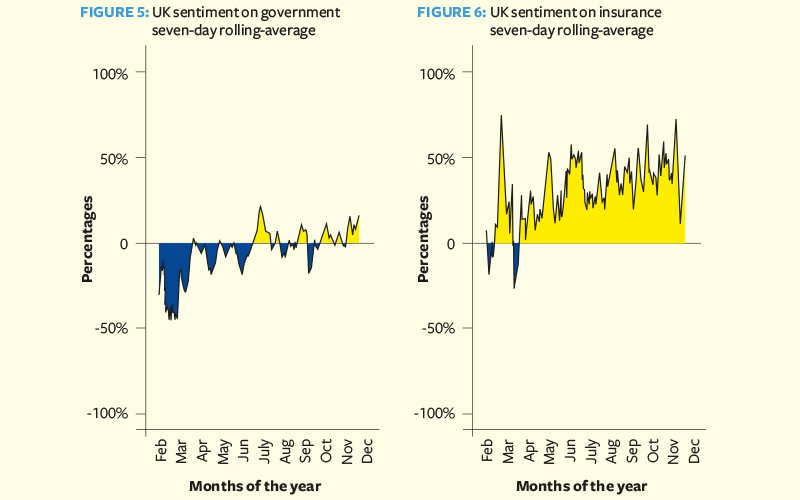
Figure 5 shows that the sentiment on government was low during the first wave, but improved and hovered around neutral from April to November. These trends are broadly consistent with University College London’s COVID-19 social study, a panel study of more than 70,000 respondents conducted via online weekly surveys. Sentiment analysis of social media could be a cost-effective tool for analysing the evolution of public opinion; traditional surveys can suffer from lower coverage and time lags. However, there are potential biases relating to the demographics of social media users as compared to the wider population.
Sentiment on insurance and insurers
Figure 6 shows a large peak in February due to an increase in tweets about travel insurance advice. The dip in March before lockdown was mainly due to government advice that asked the public to stay away from pubs and restaurants without enforcing closures, leaving businesses unable to claim insurance and liable to bankruptcy.
Many insurers are perceived negatively due to COVID-19-related claims and losses, business interruption, event cancellation, legal disputes, mismanagement of funds, and dividend cuts. Conversely, NFU Mutual, Admiral, Vitality and Cigna are examples of insurers with favourable sentiment thanks to their customer service, motor policy refunds and financial resilience. It is encouraging to see positivity towards customer service and insurer advice on mental health, exercise and workplace culture – these actions could be emulated by other insurers for the good of society.
Sentiment analysis in the insurance industry
Sentiment analysis and social media could be leveraged by insurers in their digital transformation journey. Trends can be identified from ‘voice of the customer’ analysis, leading to value proposition. For example, the pandemic could drive demand for protection products, usage-based insurance and bike insurance.
In addition, Twitter sentiment analysis is useful for reputation management, allowing insurers to monitor public opinion of their organisations, products or marketing campaigns.
Studies such as ‘Psychological language on Twitter predicts county-level heart disease mortality’ (Eichstaedt et al., 2015) and ‘Correlating Twitter language with community-level health outcomes’ (Schneuwly et al., 2019) have found Twitter language to be correlated with mortality and morbidity outcomes such as heart disease, diabetes and cancer. Inevitably, this suggests potential application in underwriting and pricing. However, this application would require rigorous checks around ethical and privacy considerations, and analysis of correlation-versus-causation effects.
Nevertheless, these methods have promising applications across the insurance value chain, including in product development, sales, marketing, competitor analysis, social profiling and, ultimately, providing better services to customers.