
Insurance: Collaboration without compromise
Originally published by The Actuary, March 2021. © The Institute and Faculty of Actuaries.
Click here to read the original article.
Małgorzata Śmietanka introduces the opportunities for federated learning and privacy-preserving data access in insurance.
Insurance companies are increasingly collecting large quantities of historic and real-time data. This includes traditional data sources, such as business, financial and economic data, as well as new data sources such as social media, mobile and wearable devices, telematics and GPS. There is also increasing collaboration on joint data analytics with third parties. The privacy of this data poses many challenges, including internal data management, collaboration with third parties, monetisation of data, data analytics, and legislation.
Internal data management
Controlling access to data is a growing priority for all organisations. Employee access to customer data is tracked and monitored in both public and private corporations. Global corporations such as Facebook have a strong incentive to protect client trust and guard against reputational damage caused by data breaches. Breach of trust when it comes to data access can lead to severe penalties, such as litigation and termination of employment.
Collaboration with third parties
Companies recognise the value of collaboration, but they need a way to collaborate without compromising sensitive ‘raw’ data access. In healthcare, for example, solving complex medical problems and creating drugs to fight diseases require companies to gather data from diverse organisations such as medical institutions, insurance companies, gyms and even supermarkets. Collaboration between healthcare institutions and the insurance sector in the future may lead to more accessible insurance products for those who suffer from rare or incurable diseases.
Monetising data
Companies are increasingly looking to monetise data that they’ve collected through business operations – for example credit card companies selling real-time anonymous credit transactions to investment companies. We can distinguish internal and external data monetisation, depending on how data is used and distributed to produce economic benefit.
Data analytics
Large amounts of data are often required to train and deploy useful machine learning (ML) models in industry. Many enterprises (especially smaller ones) do not have the luxury of gathering enough data themselves for ML models. Now, however, the total amount of information available online is incalculable, but there are other challenges associated with data, such as security and computational resources. To address those challenges, distributed ML techniques are adopted.
Legislation
Sensitive data, such as financial transactions or medical records, needs to be stored and maintained by its owners. It usually exists in isolated silos and free data circulation is prohibited, meaning data needs to be anonymised or aggregated before it is shared with a third party. Failure to adequately address the problem of data fragmentation and isolation while complying with privacy-protection laws will likely lead to a new AI winter (reduced funding and interest in AI).
Federated machine learning
This describes a new class of distributed ML models, often referred as to as federated machine learning. However, it is also increasingly acknowledged as a privacy-preserving data technology or infrastructure.
‘Distributed’ refers to decentralised multi-node systems that are designed to improve performance, increase accuracy and scale to larger input data sizes.
‘Federated machine learning’ is a distributed training approach which enables you to collaboratively train an ML model while keeping data sources in their original location. For example, mobile phone users can benefit from obtaining well-trained models without sending their personal data to the cloud.
‘Privacy-preserving data infrastructure’ is a framework for building collaborative models, allowing secure communication with collaborating parties so that data does not leave the owner.
The traditional ML model involves gathering raw data together (for example in the Cloud) for training. This is characterised as ‘taking the data to the algorithm’. Federated learning, in contrast, is ‘taking the algorithm to the data’.
By definition, federated learning aims to build a joint ML model based on data located at multiple sites. The concept was proposed by Google in 2016 in the context of privacy-preserving multiple mobile device model training. Google’s work concentrates on mobile devices model optimisation, where data is distributed over an extremely large number of nodes (Figure 1).
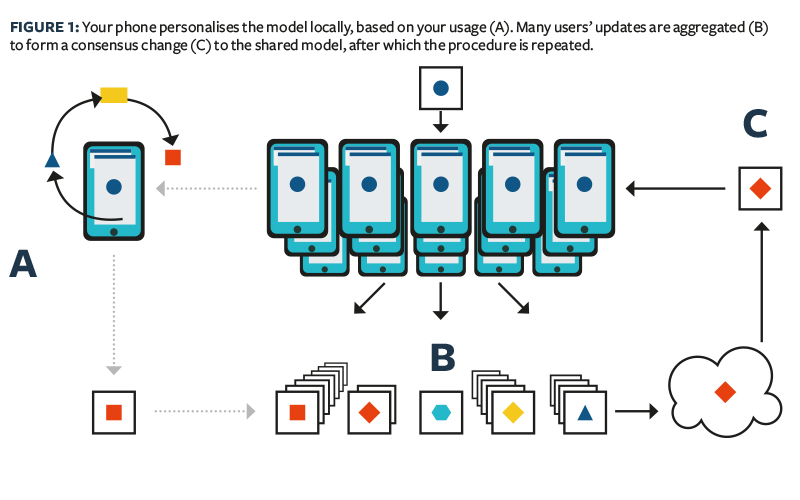
There are two processes in federated machine learning: i) model training and ii) model inference. In the process of model training, anonymised information can be exchanged between parties but the sensitive raw data cannot. The exchange does not reveal any protected private portions of the data at each site. The trained model can reside at one party or be shared among multiple parties.
At the model inference stage, the model is applied to a new data instance. Using an insurance example, a federated-fraud detection system may receive a new claim from a policyholder insured with a different company. Parties collaborate to classify the claim as legitimate or fraudulent and to predict the total future claim amount from this claim.
One way to classify federated learning is according to how data is partitioned among nodes contributing to the global model. These classifications include horizontal federated learning, vertical federated learning and federated transfer learning (Figure 2, overleaf).
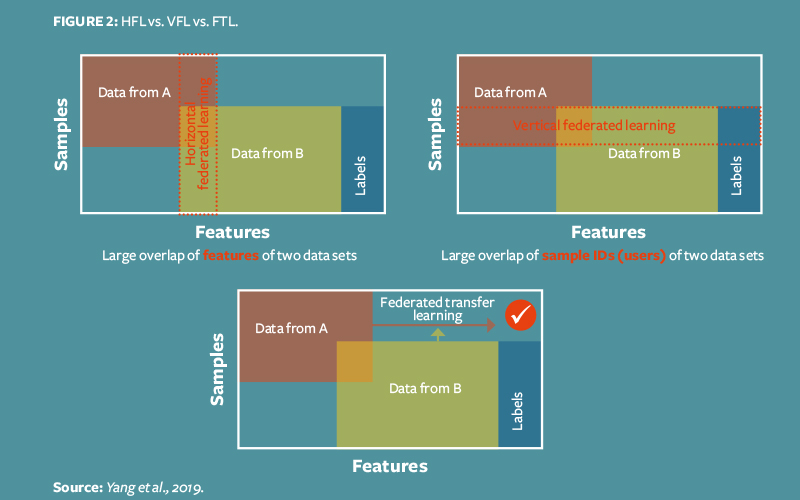
Horizontal federated learning (HFL)
This assumes that datasets from different participants share the same feature space but may not share the same sample ID space (for example Google GBoard, where data resides in different user devices but is consistent in terms of the type of information provided to train the model).
Vertical federated learning (VFL)
Participants share the same ID space but have different feature spaces, while label information (the feature we want to model using the training dataset) is owned by one participant. This is a scenario when different information about single entity is stored in distributed datasets and we want to enrich one database with information stored in the other database. One possible use case would be if two e-commerce companies and a bank were collaborating to train a model to recommend personalised loans for users based on online shopping behaviours. This could easily be adapted to insurance: for example, the NHS could collaborate with medical insurance providers to provide personalised medical insurance products.
Federated transfer learning (FTL)
Applies to the scenarios when two datasets differ in both samples and feature space.
Privacy-preserving data infrastructure Federated learning is also an algorithmic framework for building ML models characterised by the following features:
- There are at least two parties interested in jointly building an ML model. Each party holds some data that will be contributed to training the model
- In the model-training process, the data does not leave the parties
- The model can be transferred in a secured way (each party cannot re-engineer the data) under an encryption scheme
- The resulting model is a good approximation of the hypothetical ideal model trained from centralised data.
Further, we can distinguish three classes of federated learning infrastructure: closed homogenous federated learning systems, closed heterogeneous federated learning systems, and open heterogeneous federated learning systems.
Closed homogeneous federated learning systems
Federated learning across a ‘private’ network of homogeneous devices (for example Google’s mobile Android smartphones).
Closed heterogeneous federated learning systems
Federated learning across a ‘private’ network of trusted collaborating institutions, for example a group of insurance companies working on a fraud detection model, or banks wanting to offer an insurance product for their credit card holders.
Open heterogeneous federated learning systems
Federated learning services across a ‘public’ network of unverified institutions, where each institution is selling privacy-preserving (analysed) data based on its sensitive ‘raw’ data. Examples include: supermarkets selling analysed loyalty card data; a transport authority selling the anonymised travel data of its passengers; telecoms companies selling anonymised data on their subscribers; and hospitals giving analysed medical data to insurance companies to make rare diseases products more accessible.
Federated learning applications in insurance
Collaboration between insurers might bring mutual benefit in detecting fraud or more efficient claims handling. Insurers learning from transactions data owned by credit card providers could improve client targeting and develop more personalised insurance products. Collaboration with the healthcare sector may lead to better coverage of uninsured populations.
A federated learning system for improved risk pricing could work as follows:
- Different data sources are identified (credit card, loyalty cards, healthcare, wearable devices, and so on)
- Encryption mechanism of federated learning is used together with the data model that explicitly determines the structure of data
- Data owners retain control over customer data
- Insurance company trains a single pricing scoring model in federated learning environment
- A new contract is priced or a credit score is provided upon request in a federated environment.
As data privacy becomes more important because of regulation (such as the EU’s General Data Protection Regulation), there is huge potential for federated learning applications across industries. Currently we see most applications in mobile phones and healthcare, but I expect federated learning technology to spread across the insurance sector and provide the benefits of institutional collaboration.